

- 原文链接: Reactive GraphQL Architecture
- 译文出自 : 掘金翻译计划
- 译者 : shenxn
- 校对者 : lekenny,CoderBOBO
高水平设计
这是一个高度概述的响应式 GraphQL 数据加载系统的体系结构。,我们这么做的目的是希望得到那些相关领域工程师的反馈。我们想要分享我们正在做的事以确认人们是否对它感兴趣,同时使得该领域中的人能够接受我们的设计。
- 如果你还不了解我们的设计,请阅读我们的介绍页面,这个页面概述了所有我们希望解决的问题。
- 你也可以阅读 Arunoda 的文章,那篇文章总结了我们的介绍内容:Meteor’s Reactive GraphQL is Just Awesome
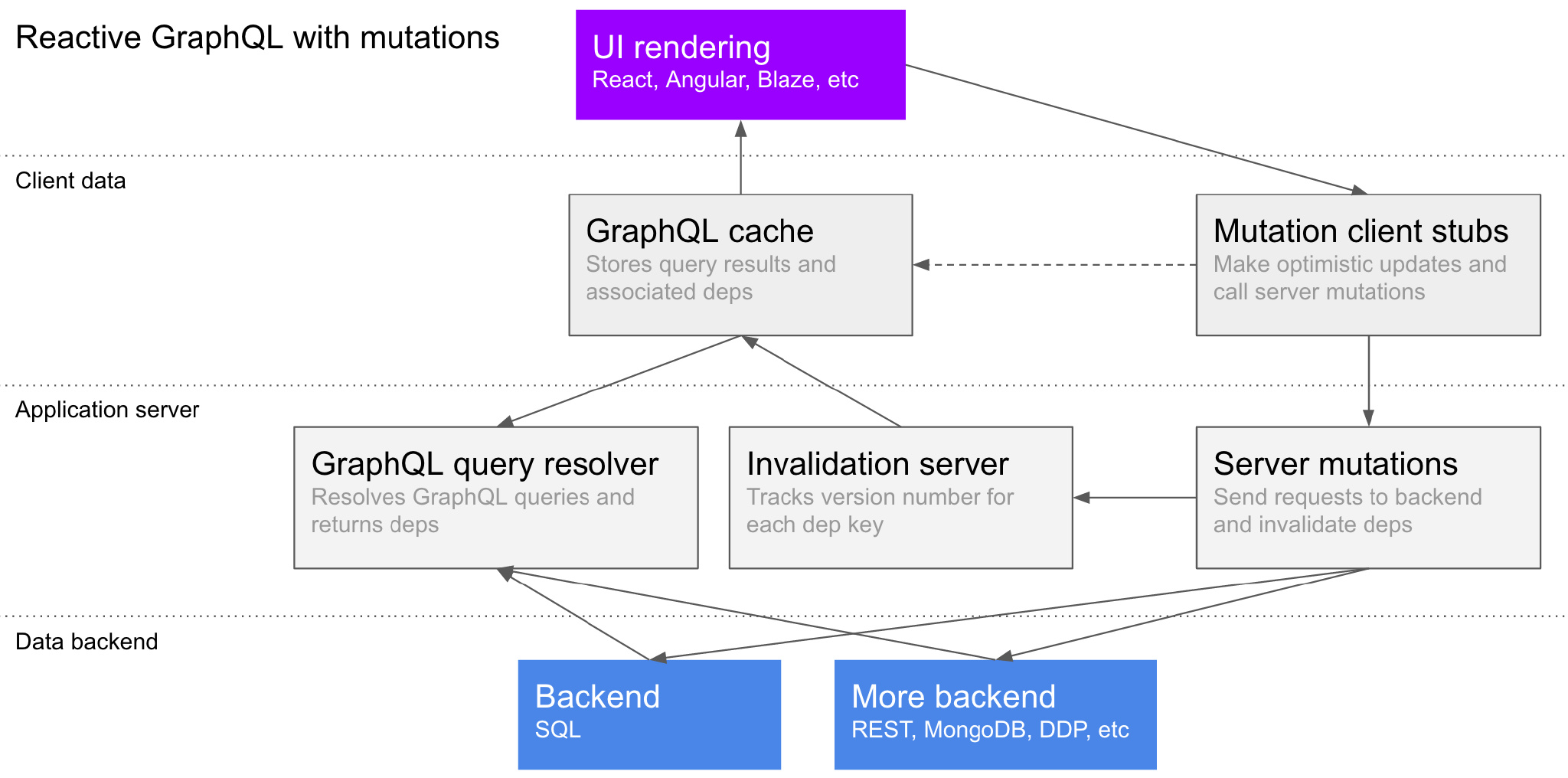
这是一张总结了我们设计的图表,之后我们会进行详细的解释:
GraphQL
(如果你已经对 GraphQL 很熟悉了,你可以跳过这个部分)
GraphQL 是一个用于查询节点类型图表的树形查询语言。举例来说,如果你有一些用户,一些待办事项列表,和一些任务,你就可以像下面这样查询:
me {
username,
lists {
id,
name,
tasks(complete: false) {
id,
content,
completed
}
}
}
查询中的每一个字段都调用了服务器上的一个可以访问任何数据源或API的解析函数。返回值被封装在一个与查询的样子类似的 JSON 响应中,并且你不会得到任何你没有查询的字段。针对上面的查询,你会得到如下数据:
{
me: {
username: "sashko",
lists: [
{
id: 1,
name: "My first todo list",
tasks: [ ... and so on ],
}
]
}
}
你可以跟随一个时长几个小时的交互式课程 LearnGraphQL 来学习 GraphQL 的基础知识。
注意,数据源是没有限制的,你可以在一个数据库中储存你的待办事项列表,并在另一个数据库中储存你的任务。事实上,GraphQL 的主要好处就是,你可以把数据从数据源中提取出来,这样前端开发者就不用担心数据源的问题了,后端开发者也可以自由地更改数据或者服务。下图展示了这种设计使用结构组件来表示的样子:
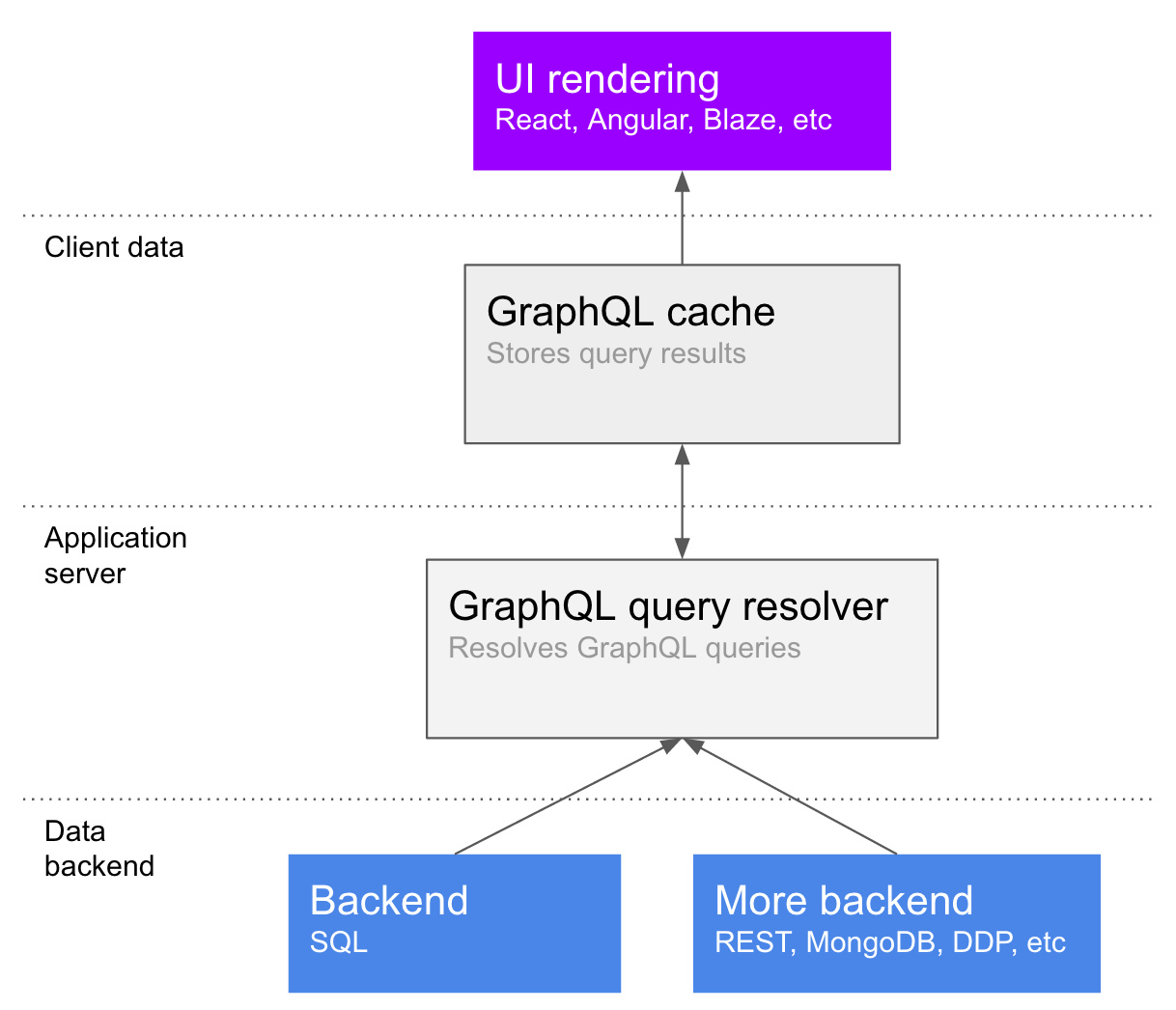
注意,GraphQL 拥有一个缓存,这个缓存是用来把查询结果分解成节点。一个聪明的缓存可以在数据需求变化或者部分数据需要刷新的时候,在之间缓存对象的基础上只重新获取查询的一部分,甚至是一个字段。在上面的例子中,缓存中的数据可能会被这样存储:
{ type: "me", username: "sashko", lists: [1] }
{ type: "list", id: 1, name: "My first todo list", tasks: [...] }
这个例子非常简明。你可以在 Huey Petersen 的网站上了解 Relay 缓存的工作方式。需要注意的是,缓存系统会将查询结果分解成平面结构,并且一个聪明的缓存将能够在必要时生成一个查询来更新 list 和它的 tasks,或者仅仅更新 list 的 name。
响应式 GraphQL
人们对 GraphQL 感到很激动,并且它解决了许多开发者(包括 Metor 的顾客和用户)遇到的许多问题。但是当你构建一个应用的时候,你不止是需要一种向服务器发起查询并得到响应的方式。举例来说,你应用的一部分可能会在另一个用户做出一些修改的时候需要响应式更新数据。
GraphQL 系统的客户端和服务器需要合作来实现上述功能,但是我们的一个目标是尽量减少对现行 GraphQL 执行方式的改变,从而使得开发者不管是现在还是将来都可以将 GraphQL 作为生产力的工具。
依赖(Dependency)
我们想象中的系统的核心观点就是依赖。一个依赖就是一个 键(key) 和 版本(version) 的元组,其中 键 在全局中代表一个特定的数据单元(比如数据库中的一条记录或是一个查询的结果),而 版本 在全局中代表数据被修改的次数。
预想中的结果是,如果你拥有一些数据,并且你有这个数据的依赖,你就可以通过发送键和版本的方式向全局依赖服务器询问数据是否已经被修改了。这样做的主要好处是,应用程序的服务器不需要知道每个客户端当前正在追踪的查询,客户端可以自己保存这些信息。这减少了服务器的负担,并且使得开发者可以更自由地选择抓取新数据的时间。
将依赖返回到客户端
之前,我们给了一个简单查询的 GraphQL 响应作为例子。如果你需要创建一个响应式的 GraphQL 查询,客户端需要需要一些额外的元数据来知道结果树中的哪些部分是响应式的,并且哪些键是无效的。客户端查询器会自动把这个元数据的字段添加到你的查询中,所以内部的响应应该会像下面这样:
{
me: {
username: "sashko",
lists: [
{
id: 1,
name: "My first todo list",
tasks: [ ... and so on ],
__deps: {
__self: { key: '12341234', version: 3 },
tasks: { key: '35232345', version: 4 }
}
}
],
__deps: {
__self: { key: '23245455', version: 1 },
lists: { key: '89353566', version: 5 }
}
}
}
这会告诉客户端哪些依赖它们应该监视来获知 list 对象本身的更改,或是 tasks 列表需要被更新。当然,这些额外的元数据会在传递给真实客户之前被过滤掉。
需要注意的是,__deps 字段不能被添加到 tasks 中,因为 JSON 语法不允许这么做,所以我们不得不把它放在父元素中。同样,__self 字段是对象的一个简略表达方式,这样就不需要列出 list 对象的所有属性(会包含 name,description 等,并且重新发送所有的键会浪费带宽)。
在读入数据时自动记录依赖
为了知道一个 GraphQL 查询在什么时候需要被重新运行,我们需要先知道哪些依赖代表了查询中的不同部分。复杂查询的依赖可以被手动记录,但是一些简单查询的依赖可以被自动识别。举例来说,这是一个可以被用在 GraphQL 解析树上特定部分中的 Javascript SQL 查询:
todoLists.select('*').where('id', 1);
这会自动记录如下的依赖:
{ key: 'todoLists:1', version: 0 }
这个依赖记录机制需要依赖跟踪服务器确认当前的版本。
手动记录依赖
如果不能通过分析请求来确认依赖,自动依赖记录机制就不能工作。在这样的情况下,开发者将需要使用任何他们喜欢的字符串来手动记录一个依赖。
举例来说,假设你有一个用来计算用户通知数量的复杂查询,你也许需要为这个数字设置一个自定义的失效键:
// 在程序的某个地方,一个用于生成键的函数
function notificationDepKeyForUser(userId) {
return 'notificationCount:' + userId;
}
// 在 GraphQL 解析器内部
numNotifications = getNotificationCountForUser(userId);
context.recordDependency(notificationDepKeyForUser(userId));
这会使得你可以手动指定通知数量被刷新的时间。有些高级用户可能会对性能有非常严格的要求,像需要计算全站的访客数量或是维护一个实时的高分表,这时他们也会选择使用手动构建依赖以更好地控制他们的数据流。
简单的响应式模型
基于上面的描述,我要介绍一个实现响应式 GraphQL 的无状态策略:
- 客户端向 GraphQL 服务器发送查询,接收到一个包含一系列依赖的响应。
- 客户端周期性查询服务器,获知依赖是否失效,服务器返回包含新版本号的依赖列表。对于一些需要更低延迟的客户端来说,可以通过使用 websocket 来订阅依赖的方式,将上述方法轻松转变成有状态的方式,具体可以查阅下面一节。
- 客户端重新抓取依赖于失效依赖的子查询树。
有许多方法可以在服务器上添加更多状态来优化系统延迟并减少客户端和服务器的通信次数,这些方法可以在之后再添加。
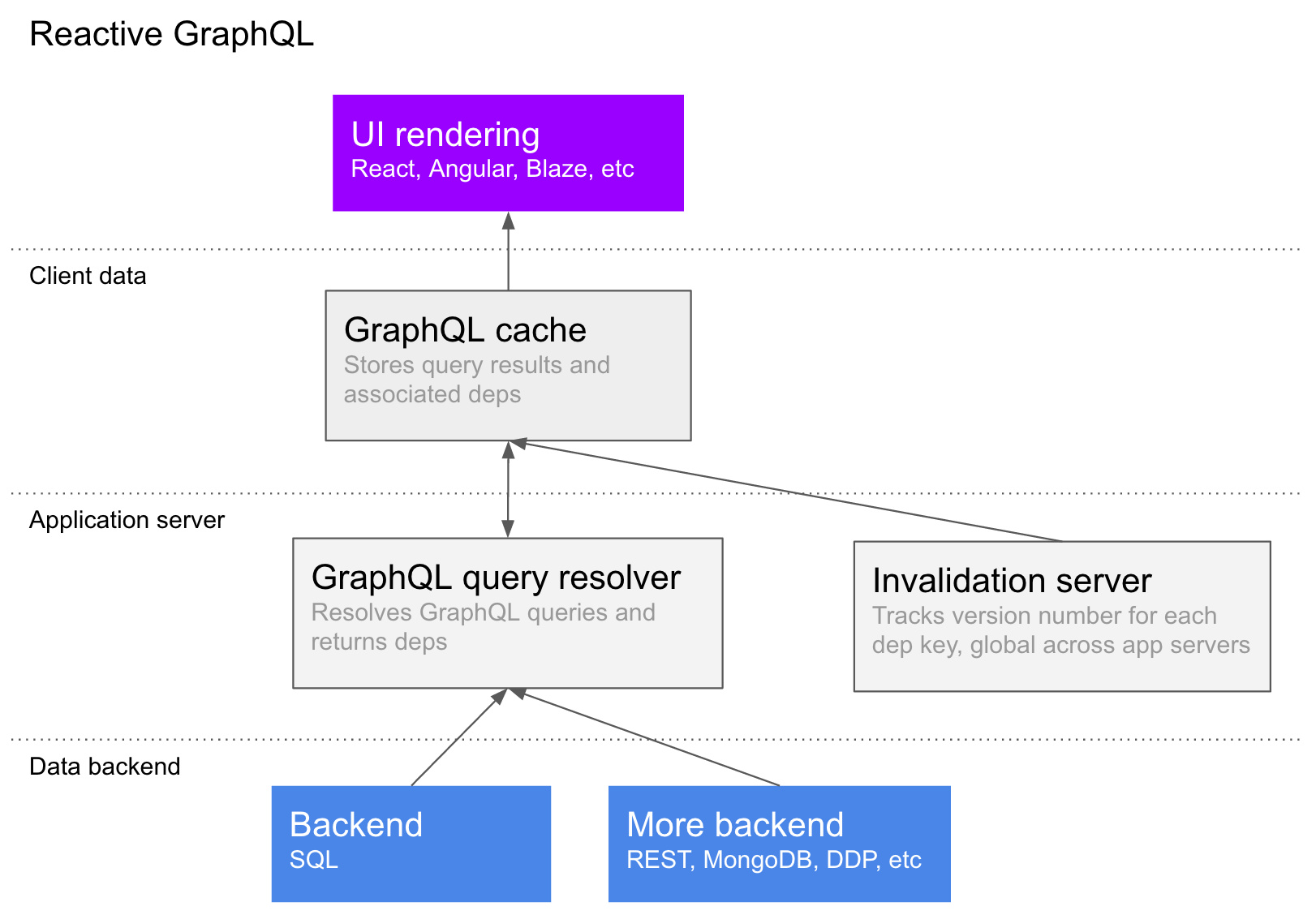
降低延迟
文档的剩余部分将会讲述从依赖服务器获取更新的话题。上面的方法导致了每次更新数据时服务器和客户端之间都需要两轮通信:一轮获取失效键,一轮获取新数据本身。下面的方法可以使得通信次数下降为1次甚至0次:
- 失效服务器可以接受 websocket 连接,并且允许客户端订阅它需要的依赖键, 这意味着失效信息是被即时推送到客户端的,并且获取数据本身只需要一轮通信。
- 让应用服务器订阅失效信息,并且在服务器上发起 GraphQL 请求,然后将请求结果与当前客户端状态进行比较并且发送一个补丁。这种方法几乎与 Meteor 现在采取的方法一致,这对于那些拥有少量用户并且要求低延迟的应用来说,是一个非常好的选择。
因为这些方法并没有修改系统的内部设计,而且非常易于执行,我们会把它们当做优化并且留到将来再处理。
使依赖失效
我们还没有讨论过失效服务器如何知道一个依赖的版本号已经增加了(这就意味着客户端上的数据需要重新加载)。最低级的方法是,你的代码在写入数据的时候,将失效的依赖列表发送给失效服务器。这部分同样也会讨论上述方法的一个高级封装。
Mutations
到目前为止,我们只讨论了如何加载数据,如果你的应用程序只是用来查看一些你不能控制的数据,这就足够了。然而,大多数应用依然需要允许他们的用户操作数据。
在 GraphQL 中,发送给服务器的数据修改请求被称为 mutation,所以我们在这篇文档中也会这样称呼它们。
mutation 是什么?
你可以把一个 mutation 想象成一个远程程序的调用点。归根结底,这就是服务器上一个函数的名称,客户端可以通过这个名称和一些相应的参数来调用函数。
在这个基于依赖的系统上,mutation 需要做这些事:
- 将数据写入后端数据库或者调用相关 API。
- 给失效服务器发送适当的失效信息。
- 可选优化更新客户端,使客户端更好地与服务器进行数据交换。
我们希望这个系统能使开发者在调用一个 mutation 的时候,可以尽可能少地操心哪些数据可能发生了变化,同时,我们也允许开发者自己处理数据的变化以便于优化。
让 mutation 发送失效信息也是做乐观 UI 的一个好方法。你可以简单地从 mutation 返回已经失效的依赖键,然后客户端就可以在需要重新获取那些依赖的时候,直接从服务器取得真实数据。
这里最大的困难是(2):mutation 如何通知失效服务器,以及通知那些数据被修改的客户端?
自动依赖失效
就像读取数据一样,在简单的情况下我们可以从 mutation 自动发送失效信息。举例来说,如果你在 mutation 解析器中执行如下 SQL 更新查询:
todoLists.update('name', 'The new name for my todo list').where('id', 1);
我们需要使得下面的依赖键失效:
'todoLists:1'
你可以看到,这对应了我们在读取这个记录时,自动记录的依赖,所以合适的请求将会重新运行。
手动依赖失效
有时你希望手动发送失效信息。举例来说,在上面通知的例子中,我们希望在添加通知时手动失效通知总数:
notifications.insert(...);
context.invalidateDependency(notificationDepKeyForUser(userId));
我们希望将来可以让程序自动处理越来越多的失效信息,但是为更复杂的情况预留一条后路让程序员进行完全的控制总是好的。
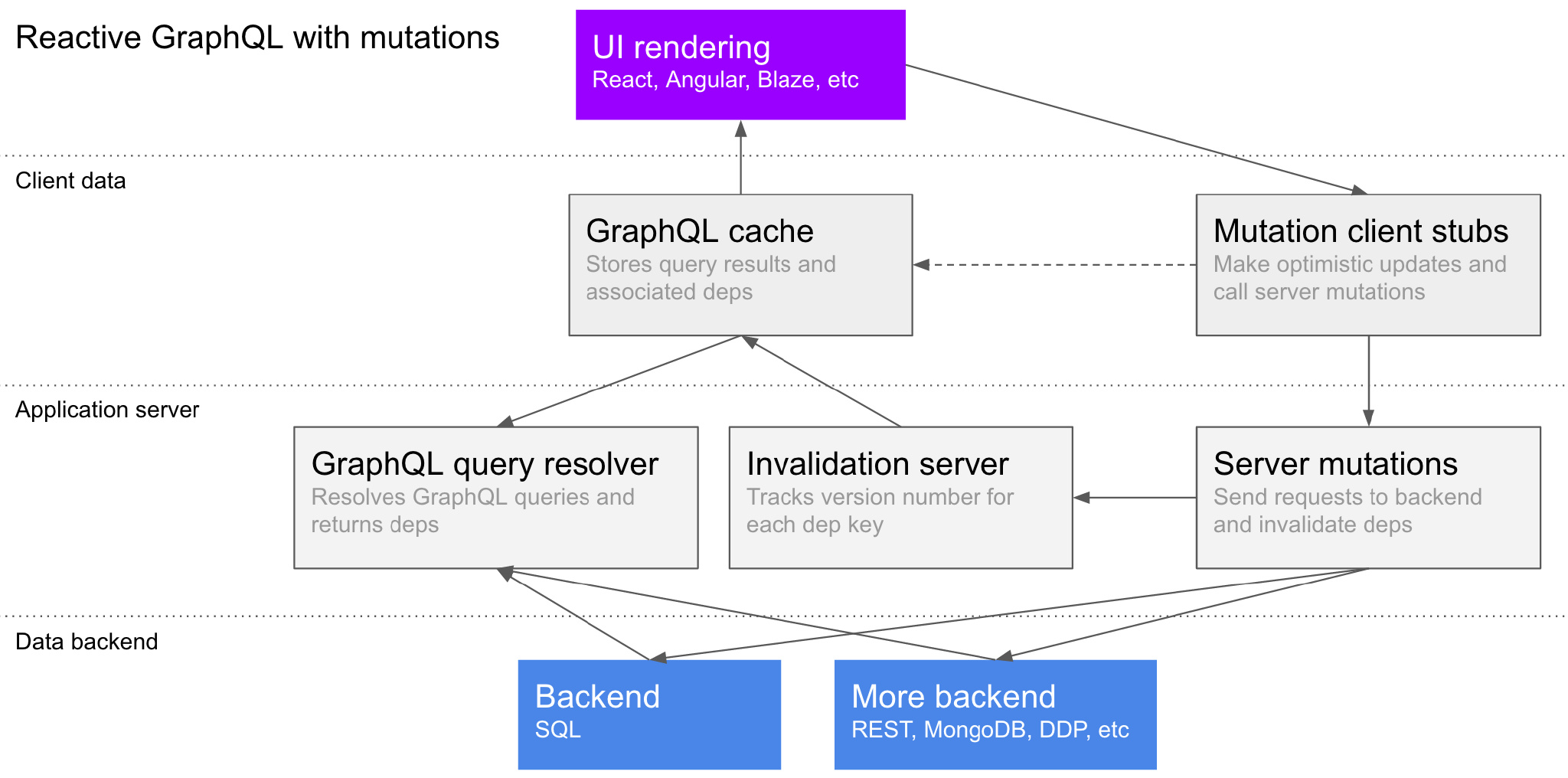
你可以通过这个图表来了解失效信息如何从 mutation 传递到相关的客户端中,客户端之后会在需要的时候重新抓取相关数据。
向外部服务写入数据
如果你的后端代码需要向外部源写入数据,你将无法使用自动失效。这意味着如果你想要你 UI 中的数据被更新,你需要做一些额外的事情来提供响应性。最简单的方式就是让进行外部数据写入的服务将失效信息直接发送给失效服务器。
另一种能使外部更新具有响应性的方法就是设置一个实时的查询执行系统,并通过监视数据库的方法来使依赖失效。举个例子,Metor 的 Livequery 可以设置成监视 MongoDB,并且在 tofoLists.find({ id: 1}) 的结果发生变化时,使 todoLists:1 失效。
系统的初始版本并不会拥有一个內建的实时查询支持,但是我们希望系统各部分中那些设计巧妙的 API 可以使这些组件很容易被集成进去。
最后,如果你觉得适用于你的应用的话,你甚至可以在不使用任何依赖的情况下,直接通过客户端轮询正确的数据。对于一些应用程序来说,加载数据本身并没有很大的开销。举个例子,如果你有一个5人使用的内部控制面板,在这种情况下实现的简单性要远比性能重要。
数据驱动
为了让这个系统更便于使用,我们需要为流行的数据源提供一些设计良好的驱动。如果你不需要响应性的话,连接到一个随意的数据源是非常简单的,你可以直接使用 NPM 中的任何数据载入包或者是写一些简单的函数来获取数据。如果要添加响应性的话,你可以使用手动的依赖记录和依赖过期。
然而,我们希望除了 Meteor 官方维护的 SQL,MongoDB 和 REST APIs 驱动之外,社区可以编写出更友好的数据驱动。
一个顶尖的开发者友好的后端数据驱动需要:
- 从数据源读取对象并且为简单查询自动记录依赖。
- 将对象写入数据源,并且在大多数情况下自动发送失效信息。
- 拥有基础的缓存以优化性能。
虽然说一个理想的驱动将能够自动为所有查询发送准确的依赖和失效信息,但是这对于一个任意的数据储存来说是不现实的。在实际情况下,驱动将会回落到一个更大范围的依赖和失效信息,并且一些工具可以帮助开发者寻找这些过期信息可以被优化的地方。然后开发者就可以根据需要重新构造他们的查询或是手动发送过期信息。
应用性能监控和优化
我们在 Metor 的系统中使用有状态的实时查询来实现响应性和订阅特性时发现,这会使得程序变得难以调试和分析。当你在调试你的程序或是试图找出性能问题时,你需要在你的服务器上重现这个问题出现的情形。如果你的服务器上有大量的状态,并且这些状态依赖于数据库当时的情况,包括你在执行哪些查询,以及哪些特定的客户端集合正在查看这些数据,这会使得你非常难以找出造成错误的原因。
这个新的系统就是设计来避免这个问题的,并且该系统的实现是从底层开始支持用于开发和生产的性能分析。我们为那些希望做性能分析的开发者设计了两条路径:
- 数据加载 页面上的一系列 UI 组件应该如何被翻译成 GraphQL 查询,以及这些查询在一系列后端数据源上如何运作。这个问题对于任何基于 GraphQL 的系统来说都很常见,但是这个问题很难被单一工具解决,因为这天生将客户端和服务器绑在了一起。
- Mutations. 在一个响应式系统中,一个 mutation 会造成一些客户端需要重新获取数据。所以跟踪 mutation 的行为是非常重要的:哪些行为从数据库加载了数据,哪些依赖过期了,以及在其他客户端上发生了哪些重取。这可以帮助你在保持你的用户拥有良好用户体验的前提下,优化你的 UI 结构、数据加载样式、响应性、以及 mutation 来减少你的服务器负担。
在你从上述两条路径分析了你的应用之后,你应该可以清楚地知道你应该通过小心地进行手动失效以及禁用响应性来优化你的程序,这会使得你能够在修改尽可能少的应用代码的前提下,极大地优化性能。
执行计划
这张图表描述了我们认为一个完整系统需要构建的所有东西:
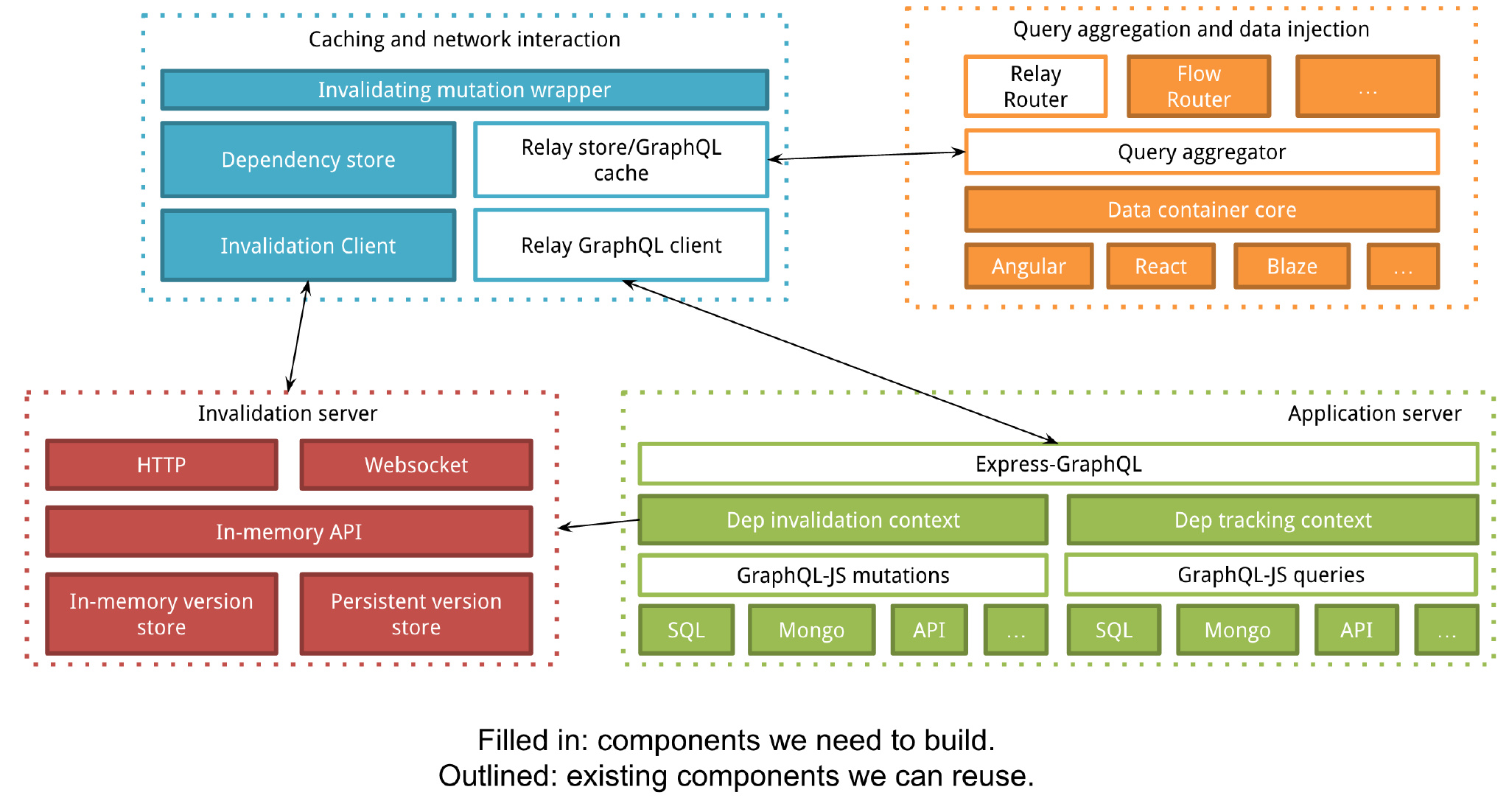
每一个组件的独立设计将会在之后的文章中讲到,举例来说,失效服务器是如何工作的?这篇文档的主要目的是概述这些组件如何一起工作。我们希望系统中的所有组件都是清晰的,并且拥有完善文档的 API,这样你就能在需要的时候为任意部分编写你自己的实现。
这将会是一个很大的工作量,但是多亏 Relay 项目,大多数工作都已经完成了,并且有些任务可以在整个竞购更清晰之后由社区贡献,比如说数据库驱动。
这是一个高度概述的响应式 GraphQL 数据加载系统的体系结构。,我们这么做的目的是希望得到那些相关领域工程师的反馈。我们想要分享我们正在做的事以确认人们是否对它感兴趣,同时使得该领域中的人能够接受我们的设计。
这是一张总结了我们设计的图表,之后我们会进行详细的解释:
GraphQL
(如果你已经对 GraphQL 很熟悉了,你可以跳过这个部分)
GraphQL 是一个用于查询节点类型图表的树形查询语言。举例来说,如果你有一些用户,一些待办事项列表,和一些任务,你就可以像下面这样查询:
me {
username,
lists {
id,
name,
tasks(complete: false) {
id,
content,
completed
}
}
}
查询中的每一个字段都调用了服务器上的一个可以访问任何数据源或API的解析函数。返回值被封装在一个与查询的样子类似的 JSON 响应中,并且你不会得到任何你没有查询的字段。针对上面的查询,你会得到如下数据:
{
me: {
username: "sashko",
lists: [
{
id: 1,
name: "My first todo list",
tasks: [ ... and so on ],
}
]
}
}
你可以跟随一个时长几个小时的交互式课程 LearnGraphQL 来学习 GraphQL 的基础知识。
注意,数据源是没有限制的,你可以在一个数据库中储存你的待办事项列表,并在另一个数据库中储存你的任务。事实上,GraphQL 的主要好处就是,你可以把数据从数据源中提取出来,这样前端开发者就不用担心数据源的问题了,后端开发者也可以自由地更改数据或者服务。下图展示了这种设计使用结构组件来表示的样子:
注意,GraphQL 拥有一个缓存,这个缓存是用来把查询结果分解成节点。一个聪明的缓存可以在数据需求变化或者部分数据需要刷新的时候,在之间缓存对象的基础上只重新获取查询的一部分,甚至是一个字段。在上面的例子中,缓存中的数据可能会被这样存储:
{ type: "me", username: "sashko", lists: [1] }
{ type: "list", id: 1, name: "My first todo list", tasks: [...] }
这个例子非常简明。你可以在 Huey Petersen 的网站上了解 Relay 缓存的工作方式。需要注意的是,缓存系统会将查询结果分解成平面结构,并且一个聪明的缓存将能够在必要时生成一个查询来更新 list 和它的 tasks,或者仅仅更新 list 的 name。
响应式 GraphQL
人们对 GraphQL 感到很激动,并且它解决了许多开发者(包括 Metor 的顾客和用户)遇到的许多问题。但是当你构建一个应用的时候,你不止是需要一种向服务器发起查询并得到响应的方式。举例来说,你应用的一部分可能会在另一个用户做出一些修改的时候需要响应式更新数据。
GraphQL 系统的客户端和服务器需要合作来实现上述功能,但是我们的一个目标是尽量减少对现行 GraphQL 执行方式的改变,从而使得开发者不管是现在还是将来都可以将 GraphQL 作为生产力的工具。
依赖(Dependency)
我们想象中的系统的核心观点就是依赖。一个依赖就是一个 键(key) 和 版本(version) 的元组,其中 键 在全局中代表一个特定的数据单元(比如数据库中的一条记录或是一个查询的结果),而 版本 在全局中代表数据被修改的次数。
预想中的结果是,如果你拥有一些数据,并且你有这个数据的依赖,你就可以通过发送键和版本的方式向全局依赖服务器询问数据是否已经被修改了。这样做的主要好处是,应用程序的服务器不需要知道每个客户端当前正在追踪的查询,客户端可以自己保存这些信息。这减少了服务器的负担,并且使得开发者可以更自由地选择抓取新数据的时间。
将依赖返回到客户端
之前,我们给了一个简单查询的 GraphQL 响应作为例子。如果你需要创建一个响应式的 GraphQL 查询,客户端需要需要一些额外的元数据来知道结果树中的哪些部分是响应式的,并且哪些键是无效的。客户端查询器会自动把这个元数据的字段添加到你的查询中,所以内部的响应应该会像下面这样:
{
me: {
username: "sashko",
lists: [
{
id: 1,
name: "My first todo list",
tasks: [ ... and so on ],
__deps: {
__self: { key: '12341234', version: 3 },
tasks: { key: '35232345', version: 4 }
}
}
],
__deps: {
__self: { key: '23245455', version: 1 },
lists: { key: '89353566', version: 5 }
}
}
}
这会告诉客户端哪些依赖它们应该监视来获知 list 对象本身的更改,或是 tasks 列表需要被更新。当然,这些额外的元数据会在传递给真实客户之前被过滤掉。
需要注意的是,__deps 字段不能被添加到 tasks 中,因为 JSON 语法不允许这么做,所以我们不得不把它放在父元素中。同样,__self 字段是对象的一个简略表达方式,这样就不需要列出 list 对象的所有属性(会包含 name,description 等,并且重新发送所有的键会浪费带宽)。
在读入数据时自动记录依赖
为了知道一个 GraphQL 查询在什么时候需要被重新运行,我们需要先知道哪些依赖代表了查询中的不同部分。复杂查询的依赖可以被手动记录,但是一些简单查询的依赖可以被自动识别。举例来说,这是一个可以被用在 GraphQL 解析树上特定部分中的 Javascript SQL 查询:
todoLists.select('*').where('id', 1);
这会自动记录如下的依赖:
{ key: 'todoLists:1', version: 0 }
这个依赖记录机制需要依赖跟踪服务器确认当前的版本。
手动记录依赖
如果不能通过分析请求来确认依赖,自动依赖记录机制就不能工作。在这样的情况下,开发者将需要使用任何他们喜欢的字符串来手动记录一个依赖。
举例来说,假设你有一个用来计算用户通知数量的复杂查询,你也许需要为这个数字设置一个自定义的失效键:
// 在程序的某个地方,一个用于生成键的函数
function notificationDepKeyForUser(userId) {
return 'notificationCount:' + userId;
}
// 在 GraphQL 解析器内部
numNotifications = getNotificationCountForUser(userId);
context.recordDependency(notificationDepKeyForUser(userId));
这会使得你可以手动指定通知数量被刷新的时间。有些高级用户可能会对性能有非常严格的要求,像需要计算全站的访客数量或是维护一个实时的高分表,这时他们也会选择使用手动构建依赖以更好地控制他们的数据流。
简单的响应式模型
基于上面的描述,我要介绍一个实现响应式 GraphQL 的无状态策略:
- 客户端向 GraphQL 服务器发送查询,接收到一个包含一系列依赖的响应。
- 客户端周期性查询服务器,获知依赖是否失效,服务器返回包含新版本号的依赖列表。对于一些需要更低延迟的客户端来说,可以通过使用 websocket 来订阅依赖的方式,将上述方法轻松转变成有状态的方式,具体可以查阅下面一节。
- 客户端重新抓取依赖于失效依赖的子查询树。
有许多方法可以在服务器上添加更多状态来优化系统延迟并减少客户端和服务器的通信次数,这些方法可以在之后再添加。
降低延迟
文档的剩余部分将会讲述从依赖服务器获取更新的话题。上面的方法导致了每次更新数据时服务器和客户端之间都需要两轮通信:一轮获取失效键,一轮获取新数据本身。下面的方法可以使得通信次数下降为1次甚至0次:
- 失效服务器可以接受 websocket 连接,并且允许客户端订阅它需要的依赖键, 这意味着失效信息是被即时推送到客户端的,并且获取数据本身只需要一轮通信。
- 让应用服务器订阅失效信息,并且在服务器上发起 GraphQL 请求,然后将请求结果与当前客户端状态进行比较并且发送一个补丁。这种方法几乎与 Meteor 现在采取的方法一致,这对于那些拥有少量用户并且要求低延迟的应用来说,是一个非常好的选择。
因为这些方法并没有修改系统的内部设计,而且非常易于执行,我们会把它们当做优化并且留到将来再处理。
使依赖失效
我们还没有讨论过失效服务器如何知道一个依赖的版本号已经增加了(这就意味着客户端上的数据需要重新加载)。最低级的方法是,你的代码在写入数据的时候,将失效的依赖列表发送给失效服务器。这部分同样也会讨论上述方法的一个高级封装。
Mutations
到目前为止,我们只讨论了如何加载数据,如果你的应用程序只是用来查看一些你不能控制的数据,这就足够了。然而,大多数应用依然需要允许他们的用户操作数据。
在 GraphQL 中,发送给服务器的数据修改请求被称为 mutation,所以我们在这篇文档中也会这样称呼它们。
mutation 是什么?
你可以把一个 mutation 想象成一个远程程序的调用点。归根结底,这就是服务器上一个函数的名称,客户端可以通过这个名称和一些相应的参数来调用函数。
在这个基于依赖的系统上,mutation 需要做这些事:
- 将数据写入后端数据库或者调用相关 API。
- 给失效服务器发送适当的失效信息。
- 可选优化更新客户端,使客户端更好地与服务器进行数据交换。
我们希望这个系统能使开发者在调用一个 mutation 的时候,可以尽可能少地操心哪些数据可能发生了变化,同时,我们也允许开发者自己处理数据的变化以便于优化。
让 mutation 发送失效信息也是做乐观 UI 的一个好方法。你可以简单地从 mutation 返回已经失效的依赖键,然后客户端就可以在需要重新获取那些依赖的时候,直接从服务器取得真实数据。
这里最大的困难是(2):mutation 如何通知失效服务器,以及通知那些数据被修改的客户端?
自动依赖失效
就像读取数据一样,在简单的情况下我们可以从 mutation 自动发送失效信息。举例来说,如果你在 mutation 解析器中执行如下 SQL 更新查询:
todoLists.update('name', 'The new name for my todo list').where('id', 1);
我们需要使得下面的依赖键失效:
'todoLists:1'
你可以看到,这对应了我们在读取这个记录时,自动记录的依赖,所以合适的请求将会重新运行。
手动依赖失效
有时你希望手动发送失效信息。举例来说,在上面通知的例子中,我们希望在添加通知时手动失效通知总数:
notifications.insert(...);
context.invalidateDependency(notificationDepKeyForUser(userId));
我们希望将来可以让程序自动处理越来越多的失效信息,但是为更复杂的情况预留一条后路让程序员进行完全的控制总是好的。
你可以通过这个图表来了解失效信息如何从 mutation 传递到相关的客户端中,客户端之后会在需要的时候重新抓取相关数据。
向外部服务写入数据
如果你的后端代码需要向外部源写入数据,你将无法使用自动失效。这意味着如果你想要你 UI 中的数据被更新,你需要做一些额外的事情来提供响应性。最简单的方式就是让进行外部数据写入的服务将失效信息直接发送给失效服务器。
另一种能使外部更新具有响应性的方法就是设置一个实时的查询执行系统,并通过监视数据库的方法来使依赖失效。举个例子,Metor 的 Livequery 可以设置成监视 MongoDB,并且在 tofoLists.find({ id: 1}) 的结果发生变化时,使 todoLists:1 失效。
系统的初始版本并不会拥有一个內建的实时查询支持,但是我们希望系统各部分中那些设计巧妙的 API 可以使这些组件很容易被集成进去。
最后,如果你觉得适用于你的应用的话,你甚至可以在不使用任何依赖的情况下,直接通过客户端轮询正确的数据。对于一些应用程序来说,加载数据本身并没有很大的开销。举个例子,如果你有一个5人使用的内部控制面板,在这种情况下实现的简单性要远比性能重要。
数据驱动
为了让这个系统更便于使用,我们需要为流行的数据源提供一些设计良好的驱动。如果你不需要响应性的话,连接到一个随意的数据源是非常简单的,你可以直接使用 NPM 中的任何数据载入包或者是写一些简单的函数来获取数据。如果要添加响应性的话,你可以使用手动的依赖记录和依赖过期。
然而,我们希望除了 Meteor 官方维护的 SQL,MongoDB 和 REST APIs 驱动之外,社区可以编写出更友好的数据驱动。
一个顶尖的开发者友好的后端数据驱动需要:
- 从数据源读取对象并且为简单查询自动记录依赖。
- 将对象写入数据源,并且在大多数情况下自动发送失效信息。
- 拥有基础的缓存以优化性能。
虽然说一个理想的驱动将能够自动为所有查询发送准确的依赖和失效信息,但是这对于一个任意的数据储存来说是不现实的。在实际情况下,驱动将会回落到一个更大范围的依赖和失效信息,并且一些工具可以帮助开发者寻找这些过期信息可以被优化的地方。然后开发者就可以根据需要重新构造他们的查询或是手动发送过期信息。
应用性能监控和优化
我们在 Metor 的系统中使用有状态的实时查询来实现响应性和订阅特性时发现,这会使得程序变得难以调试和分析。当你在调试你的程序或是试图找出性能问题时,你需要在你的服务器上重现这个问题出现的情形。如果你的服务器上有大量的状态,并且这些状态依赖于数据库当时的情况,包括你在执行哪些查询,以及哪些特定的客户端集合正在查看这些数据,这会使得你非常难以找出造成错误的原因。
这个新的系统就是设计来避免这个问题的,并且该系统的实现是从底层开始支持用于开发和生产的性能分析。我们为那些希望做性能分析的开发者设计了两条路径:
- 数据加载 页面上的一系列 UI 组件应该如何被翻译成 GraphQL 查询,以及这些查询在一系列后端数据源上如何运作。这个问题对于任何基于 GraphQL 的系统来说都很常见,但是这个问题很难被单一工具解决,因为这天生将客户端和服务器绑在了一起。
- Mutations. 在一个响应式系统中,一个 mutation 会造成一些客户端需要重新获取数据。所以跟踪 mutation 的行为是非常重要的:哪些行为从数据库加载了数据,哪些依赖过期了,以及在其他客户端上发生了哪些重取。这可以帮助你在保持你的用户拥有良好用户体验的前提下,优化你的 UI 结构、数据加载样式、响应性、以及 mutation 来减少你的服务器负担。
在你从上述两条路径分析了你的应用之后,你应该可以清楚地知道你应该通过小心地进行手动失效以及禁用响应性来优化你的程序,这会使得你能够在修改尽可能少的应用代码的前提下,极大地优化性能。
执行计划
这张图表描述了我们认为一个完整系统需要构建的所有东西:
每一个组件的独立设计将会在之后的文章中讲到,举例来说,失效服务器是如何工作的?这篇文档的主要目的是概述这些组件如何一起工作。我们希望系统中的所有组件都是清晰的,并且拥有完善文档的 API,这样你就能在需要的时候为任意部分编写你自己的实现。
这将会是一个很大的工作量,但是多亏 Relay 项目,大多数工作都已经完成了,并且有些任务可以在整个竞购更清晰之后由社区贡献,比如说数据库驱动。
